Zhihu
作者:彭颖鸿 链接:https://www.zhihu.com/question/21229371/answer/97495325 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
做过各种数据的预测,发现用一般的机器学习(SVR, randomForest, lasso,xgboost等等)都有这样的特点,乍一看拟合效果和预测效果都不错,pmse也很小。
但如果把预测图画出来仔细看相位的话,会发现很多时候你的预测结果其实只是真实值平移了一个时间单位。数据的频率越高,这个类似平移的延迟效应越明显,特别是金融数据,哪怕加入了其它外生特征。
看过很多机器学习与时间序列相关论文,都在夸自己的模型多牛逼多厉害,都把预测误差弄得很小很小,却很少论文真的把预测值和真实值的图仔细分析一遍。只要稍微注意看一眼,就会发现预测值真的很像是把前一天的真实值往后平移了一下而已……
个人理解是这些模型都认为对明天最好的预测就是今天的数值,E(Xn|X_n-1,...)=X_n-1…
所以,评价一个时间序列预测模型的好坏,只看平均预测误差的都是耍流氓……个人感觉机器学习在时间序列上的效果有时候还不如传统的状态空间模型……
扯远了。在问有什么模型能够预测之前,记得先做随机性检验呀,多个相互延迟的序列的相关性呀之类的,不然人家本来就没啥规律,或者说你找来的特征根本没啥影响,硬要上模型,结果弄了半天的feature engineering发现啥效果都没有,然后继续去试其它模型,简直是在浪费生命hhh……
考虑周期(如加入季节因素,正余弦项等)分组,分层,变系数,local model with kernel,有时候会有奇效。
作者:李轶睿 链接:https://www.zhihu.com/question/21229371/answer/96978182 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
个人在伦敦就是天天干这个的。通过机器学习(machine learning)做价格预测。 希望能提供一些最基础的建议(不好意思中文不是母语,很多中文术语不太清楚,所以要用一些英文)
1)首先尽量简化数据,让每一个输入都有很规范的格式。额日俄每一个输入源必须是mean 0,variance 1。假如说不能直接用价格;要用价格的差距。这样才可以客观比较每个输入的作用。而且很多模型本来就有这个要求。
2)先排除那些没有用的输入。这很简单。把数据重新re-sample,得到两个对应的time series,A和B。算两个time series的correlation。当然这个值越大越好。但是还有更有用的技巧:给其中的一列A添加offset。试着用各个offset再得出correlation。你会发这个offset过小过大,correlation就越小了。但是中间有一个达到最高值的offset。那就是A领先与B的平均时间。这offset小于零,说明A可以预测B。大于零说明这数据根本没什么预测能力,反而B更能预测A。通过这个可以筛选掉好多东西。
3)现在你得到一套最具有预测能力的输入。但他们的weighting还不知道。首先肯定要去试着用最简单的linear model。如果你的linear model没用,那更高级的模型肯定也没用了,应该放弃。这linear算法的目标就是简单地得出一列weightings对吧。在某个时刻,这一列数字乘与‘现在’的value必须和未来的value有很大的correlation。所以选择一个心目中最合适的offset(假如一秒或一小时);然后直接算各个因素的correlation。拼成一列weightings。就这么简单。也可以试着不同offset,看看这模型最好能预算多久以后的value。这东西就叫linear regression。
4)在linear regression得到成果以后,再想象更复杂的模型。建议先从一个维度升级到两个维度。得到一个矩阵的weightings。说实话这应该已经够的了。不过如果必要追求再复杂一点的话,那真的建议decision tree。decision tree也可以理解成heirarchical model(层次模型?)。比如这个情况:你发现A或B越高能预测到C要涨,但好像A和B都太高的话,C反而要跌。所以必须有层次的。这decision tree里面最推荐用random forest。这样能够在复杂程度与预测准确度之间达到最平衡的效果。
5)再高级一点就是通过完全自由连接的graph,比如neural network。但是肯定先从简单的开始。如果直接用graph,因为connections太多太密集太复杂,很多循环之类的,导致人家很难以理解里面信息运转的道理。最好从linear到2D开始,这样每一步都更加理解数据之间的关系,更好去设计适合的结构。
6)其他的一些想法:不一定要只根据时间去预测。你所根据的时间线只需要是一个越来越大的某个东西。也可以是市场的买卖量之类的。因为买卖总量和时间一样的,只往前不往后。这样的话你不在预测多少时间以后的value而在预测多少买卖增加以后的value了。一般都比较合适。
还有一点就是:你的那个数据似乎是波浪类型的。这就没有符合第一点。应该转换成更基本的输入和输出;例如分成wavelength和amplitude两个预测对象。
作者:Rand Xie 链接:https://www.zhihu.com/question/21229371/answer/98790778 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作为一个搞system identification的人来回答一下. 我觉得可以根据系统的性质简单分成两种情况:
(1) 物理系统, 或者你知道系统有特定的结构. 比如你要用time series model去fit一个物理系统. 如果你能从first principle推导出系统的动力学方程, 那就直接做参数推断. 一般来说, 加入这些knowledge是精度最高的. 不过需要花时间去推导dynamic equation
(2) 复杂系统, 难以获得精确模型(金融市场, 化工管道....). 这个时候, 我们只能依赖data driven model去capture system的dynamics. 这里又能分成线性模型和非线性模型:
(a) ARMA, ARIMA, ARMAX这些模型能较好得捕捉线性系统的dynamics, 是有很好的理论依据的. 就算是非线性系统, 也可以分段fit这些线性模型(相当于在特定时间对系统做线性化). 通常也能获得比较好的结果. 这类模型应该是现实里面用得最多的.
(b) 至于非线性模型, 大家想到的应该就是RNN, 是表达能力很强的一个模型. 但是RNN的training比较困难, 同时RNN的参数选择(layer, activation function, hidden neuron, learning rate)都难以优化. 也有的人在线性模型上加上一些非线性项(polynomial....)来提高线性模型在非线性区间的表现
单纯说高精度很难确定怎么选择模型, 不过我应该会按first principle model -> 线性模型 ->非线性模型这个顺序去尝试. 只要模型达到我的预测/控制要求, 就不会再加复杂度
最后, 关于machine learning在time series model上的应用, 我目前看到有两个做法感觉还算合理: 一个是做ensemble learning, 把不同的模型ensemble起来降低variance. 我的朋友尝试过, 说能有提高. 第二是金融那边, 对参数加入Prior, 然后用MCMC来推断模型参数. 这种方法可以结合你对系统的理解. 至于更fancy的模型,比如manifold learning啥的, 还没搞懂, 也不好评论......
高级指数平滑方法可以研究一下,ets模型等等,这方面只有英文材料,你得去google搜一下。
对于纯粹时间序列预测,目前最理想的方法应该就是RNN及其变体了。标准的RNN要达到好的效果会比较难训练,目前它的带记忆的变体,比如LSTM(long-short term memory)和GRU(gated recurrent unit)都非常热门。进一步的,这些模型还可以和其它神经网络模型组合,比如在LSTM下面堆叠若干层的CNN等等,这样基本上就是目前深度学习(deep learning)中常见的处理时间序列最好的模型了。当然这也要配置和训练得当才能得到好的效果(包括数据预处理、恰当的参数等)。建议可以少用一些数据,用Theano ( Welcome — Theano 0.8.0 documentation ) 之类的容易上手的工具包先试试看。
Recurrent Neural Network (回流神经网络,有的译做递归神经网络,应该是误译,因为recurrent不是recursive,而且网络结构也确实不是递归而是回流的)
RNN可以通过t个历史记录预测t+1,最简单的RNN叫做Elman Network。Elman Network的预测能力不强但是有利于搞清楚RNN基本结构。
现实中的RNN因为层次较深,比较难优化,单纯的BPTT(back-propagation through time)容易出现问题。最近二阶优化方法在这方面有很大的改进。
预测的是趋势,最好还是用先导变量作回归来预测。比如a可以影响n期后的b,那我们就用a来预测b。a与滞后b间是因果关系最好,是相关关系也行就是结果可能会不稳定,但是为了提升拟合度一般会找很多可以影响滞后b的变量,所以很难保证变量间的关系都是因果关系。 如果是预测平稳的波动,那就用加窗傅里叶,小波分析,arma等来做吧。
从纯时间序列的角度上来说的话,GARCH模型不错。金融时间序列方差是变化的(违背了同方差的假设)。GARCH模型允许方差随时间变化,效果一般比ARMA ARIMA AR之类的好。比较好用的模型是EGARCH。然后就时间序列来说,这些比较算中等的吧。
比如你要考虑不同市场不同股票之间的联系(存在covariance),那你可以用multivariate GARCH类的模型,这类模型是矩阵回归,并且允许存在协方差。
有兴趣的话去买本汉密尔顿的时间序列看吧,中文版100来块。
作者:大玮 链接:https://www.zhihu.com/question/21229371/answer/102318756 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我也涉及一点点时序预测,在我知识所及范围内说一下吧。如之前某位仁兄所说,如果知道系统的动力学模型的话(一般是一系列微分方程组,用泰勒展开离散化)就好办了,只需要用观测到的时序数据做模型参数估计就行。 这种情况下预测是最好的,可以做long-term prediction. 什么KF, EKF, UKF, Particle filter随便用。根据经验,还是EKF最好用,particle filter最差,估计一个参数还行,估计两个或三个参数就不好,参数收敛不到真值,而且如果迭代次数很多,会出现严重粒子贫化问题。
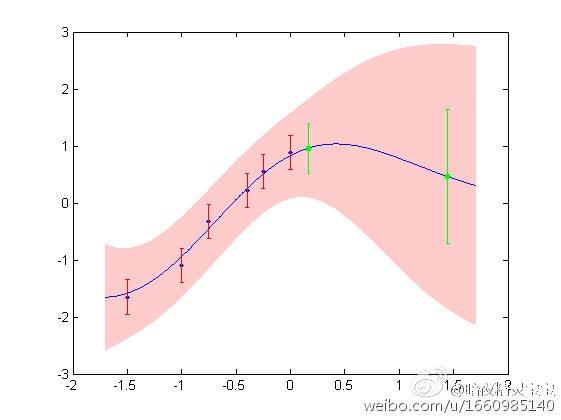
如果没有动力学方程,就只能基于数据做data-driven的预测。之前看过一些neural network做时序预测的代码以及论文,感觉他们说的prediction就是往前一步预测,或者很短时间段的short-term prediction。预测的时间段一长就完全崩溃 (也许我学识浅薄,感觉所谓data-driven prognosis都是忽悠,但是看上去都很高大上)。尝试过Gaussian process regression(GPR)建时序模型,但是GPR模型在有数据的地方做内插值(interpolation) 还比较好,在没有数据做的“未来”时刻(extrapolation)预测的方差很大,也只能short-term prediction, 比如下面这张图,在观测数据(蓝色点)附近,预测平滑方差较小,但是在没有观测点的“未来时刻”(绿色点),估计方差就很大,而且离数据越远,方差越大。就好比今天阴天,推测明天也阴天,但是十天后啥天气呢?谁也说不准了。
ARIMA是常用的一种,被用于类似风速的非平稳时间序列预测。更多用到的是组合预测,几种模型混合使用。
Recurrent Nerual Network之流前几年就被用过了。去年见有人用Auto Encoder。这些大概都属于‘深度学习’了吧。吹牛用。
效果和数据集有关,不存在包治百病的药。严格来说,世间有什么是能被预测如此之准呢?大概目前常见的就是天气预报了。
关键不在这些模型,在于对问题本质的了解。这些所谓机器学习只是没办法才用的吧;靠算命,多无聊。